Expert DevOps Interview Questions to Help You Land Your Dream Job!!
- Yajendra Prajapati
- Apr 20, 2023
- 21 min read

In today's fast-paced technology world, DevOps plays a crucial role in software development and delivery. As organizations are adopting DevOps practices, it's becoming increasingly important for job candidates to have a deep understanding of the principles and tools associated with DevOps. In this article, we'll explore some of the most common DevOps interview questions that experienced candidates can expect to face during the job interview process. By reviewing these questions and preparing thoughtful answers, you'll be better equipped to showcase your expertise and land your dream DevOps job.
Q1. What is your experience with infrastructure as code (IaC) tools like Terraform or CloudFormation?
Infrastructure as code (IaC) manages and provides IT infrastructure through code rather than manual processes. IaC tools like Terraform and CloudFormation help developers and system administrators define, create and programmatically manage infrastructure resources.
Terraform is an open-source IaC tool that allows users to define infrastructure resources as code and manage them through a consistent workflow. Terraform supports many cloud providers, including AWS, Azure, Google Cloud, and more.
CloudFormation is a service provided by Amazon Web Services (AWS), allowing users to model and provision AWS infrastructure resources as code. CloudFormation uses a JSON or YAML template to define and manage resources, and it supports many AWS services.
Both tools have their strengths and weaknesses and are popular choices among developers and system administrators. Terraform is known for its flexibility and cross-cloud compatibility, while CloudFormation offers tighter integration with AWS services and the ecosystem.
Q2. Describe your experience with containerization tools like Docker or Kubernetes.
Docker is a platform that allows developers to create, deploy, and run applications in a containerized environment. Containers are lightweight and portable, making them a popular choice for deploying and scaling applications. Docker provides a simple way to package an application and its dependencies into a container, which can be run on any machine that supports Docker.
Kubernetes, commonly called K8s, is an open-source container orchestration platform that automates containerized applications' deployment, scaling, and management. Kubernetes provides a way to manage multiple containers as a single unit, making it easier to deploy and scale applications in a cluster environment.
Kubernetes is designed to work with Docker and other containerization tools, providing a powerful platform for managing and orchestrating containers in a production environment. It offers many features, including load balancing, auto-scaling, rolling updates, and self-healing, making it a popular choice for managing large-scale containerized applications.
Both Docker and Kubernetes have become popular tools for modern application development and deployment. Docker simplifies the process of packaging and running applications in containers, while Kubernetes provides a platform for managing and orchestrating those containers at scale.
Q3. What is your experience with configuration management tools like Ansible or Puppet?
Configuration management tools like Ansible and Puppet are used to automate the deployment and management of software and system configurations across multiple servers. These tools provide a way to define the desired state of a system and ensure that it stays in that state.
Ansible is an open-source configuration management tool that uses a simple YAML-based language to define system configurations. It provides a way to automate software deployment, manage system configurations, and perform ad-hoc tasks across multiple servers.
Puppet is another open-source configuration management tool that uses a declarative language to define system configurations. It provides a way to manage the entire lifecycle of software and system configurations, from deployment to updates and beyond.
Both Ansible and Puppet have become popular choices for automating system configuration management in large-scale environments. They offer powerful features for managing system configurations across multiple servers, including idempotency, which ensures that system configurations are consistent across all servers, and role-based configuration management, which provides a way to manage configurations at a granular level.
Q4. What is your experience with cloud computing platforms like AWS or Azure?
Cloud computing platforms like AWS (Amazon Web Services) and Azure (Microsoft Azure) provide a range of services for computing, storage, and networking in the cloud. These platforms allow businesses and individuals to quickly and easily deploy and scale applications and services without having to manage the underlying infrastructure.
AWS is the most popular cloud computing platform, offering a wide range of services, including computing, storage, database, analytics, and machine learning. AWS allows users to choose from a variety of services and pricing models, making it easy to find the right solution for their needs.
Azure is another popular cloud computing platform offering similar services to AWS, including computing, storage, database, and machine learning. Azure also provides tight integration with Microsoft's other products and services, making it a popular choice for organizations that use Microsoft technologies.
Both AWS and Azure have become popular choices for cloud computing, providing powerful features and services for deploying and scaling applications in the cloud. They offer a range of pricing models, from pay-as-you-go to reserved instances, making it easy to find a solution that fits your budget and requirements.
Q5. Explain the difference between continuous integration and deployment (CI/CD).
Continuous Integration (CI) and Continuous Deployment (CD) are two related but distinct practices in software development. CI is the practice of frequently and automatically building and testing code changes, while CD is the practice of automatically deploying those changes to production.
CI is integrating code changes into a shared repository regularly, usually multiple times per day. This involves automatically building and testing code changes as they are made to catch issues early in the development cycle. CI helps ensure that code changes are consistent with the existing codebase and don't introduce new bugs or other issues.
The CD takes the process of CI one step further by automating the deployment of code changes to production. This involves using automated deployment tools and pipelines to automatically deploy changes to production as soon as they pass the necessary tests and checks. The CD helps ensure that code changes are quickly and safely deployed to production, reducing the time between development and delivery and increasing the speed of innovation.
CI/CD forms a continuous software delivery pipeline that enables developers to quickly and safely deliver new features and updates to users. CI ensures that code changes are properly tested and integrated, while CD ensures that those changes are quickly and safely deployed to production, minimizing the risk of errors and downtime.
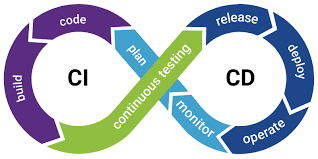
Source - Synopsys
Q6. What is your experience with version control systems like Git?
Git is a widely-used distributed version control system that allows developers to track changes to their code over time. With Git, developers can store their code in a repository and track all changes made to the code over time. Git allows developers to collaborate on code with others, track changes made by multiple contributors, and easily roll back changes if necessary.
Git works by creating a snapshot of the code each time a change is made. These snapshots, known as commits, are stored in a repository with metadata about the change, such as the author, the date, and a commit message describing the change. Git allows developers to create branches, and separate versions of the code that can be modified independently. This allows for parallel development and experimentation without affecting the main codebase.
Git is widely used in software development and is often integrated with other tools and services, such as continuous integration and deployment pipelines, code review tools, and project management systems. It is an essential tool for managing code and collaborating with other developers in a modern software development environment.
Q7. What are some best practices for managing code branches in Git?
Managing code branches in Git can be a complex task, but several best practices can help ensure that code changes are properly managed and integrated. Here are some key best practices for managing code branches in Git:
Keep the main branch stable: The main branch, usually called "master" or "main", should always be stable and ready for deployment. Avoid committing directly to this branch and use feature branches to work on new features or changes.
Use feature branches: Create a new branch for each feature or change you are working on. This allows you to work on the changes independently without affecting the main branch.
Keep branches small and focused: Each branch should contain a small, focused set of changes that can be easily reviewed and tested. Large and complex branches can be difficult to manage and may introduce errors.
Merge frequently: Merge changes back to the main branch frequently to ensure that changes are properly integrated and tested. This also helps avoid conflicts and makes it easier to track changes over time.
Review code changes: Before merging changes back to the main branch, review the code changes carefully to ensure that they are properly tested, documented, and meet the requirements.
Use Git hooks: Git hooks are scripts that run automatically when certain Git events occur, such as a commit or a merge. Use Git hooks to automate tasks such as running tests, formatting code, or checking for security vulnerabilities.
By following these best practices, you can ensure that code changes are properly managed and integrated and that the main branch remains stable and ready for deployment.
Q8. What is your experience with monitoring tools like Nagios or Prometheus?
Nagios is an open-source monitoring system that allows users to monitor their IT infrastructure, including servers, applications, and network devices. Nagios can monitor various metrics, including CPU usage, memory usage, disk space, network traffic, and application availability. Nagios can send alerts via email or SMS when certain thresholds are exceeded, allowing users to take action before issues escalate.
Prometheus is an open-source monitoring and alerting system that focuses on time-series data. Prometheus can collect metrics from various sources, including applications, services, and network devices, and can store the data in a time-series database. Prometheus also includes a flexible alerting system that can send alerts to various channels, including email, Slack, and PagerDuty.
Both Nagios and Prometheus are widely used in production environments to monitor IT infrastructure and ensure that systems run smoothly. These tools are often integrated with other systems, such as logging and visualization tools, to provide a complete monitoring and troubleshooting solution.
Q9. What is your experience with log management tools like ELK Stack or Splunk?
ELK Stack is a popular open-source log management tool that includes Elasticsearch, Logstash, and Kibana. Elasticsearch is a search and analytics engine that can store and search large volumes of data, Logstash is a data processing pipeline that can collect, parse, and enrich data, and Kibana is a web interface for visualizing and analyzing data.
Splunk is a proprietary log management tool that collects, analyses, and visualizes machine-generated data, including logs, metrics, and events. Splunk can search and analyze data in real time and includes various monitoring, alerting, and reporting features.
Both ELK Stack and Splunk are widely used in production environments to manage and analyze logs, troubleshoot issues, and monitor systems. These tools can help identify and resolve issues quickly by providing insights into application and system behaviour, identifying patterns and trends in log data, and correlating events across multiple systems. They can also help improve system performance by identifying and addressing bottlenecks and inefficiencies.
Q10. What is your experience with serverless computing?
Serverless computing is a model in which the cloud provider manages the infrastructure and automatically provisions and scales resources as needed. Instead of deploying and managing servers, developers can focus on writing code and deploying applications to the cloud provider's platform, which automatically handles tasks such as resource allocation, load balancing, and scaling.
Serverless computing typically involves deploying code in the form of functions, which are small units of code that can be executed in response to events, such as a user request or a scheduled job. The cloud provider charges based on the number of function executions and the number of resources used rather than charging for fixed instances or servers.
Serverless computing can offer several benefits, including reduced operational overhead, improved scalability, and lower costs. It can also enable faster development and deployment cycles, as developers can focus on writing code and testing functionality without worrying about managing infrastructure.
Some popular serverless computing platforms include AWS Lambda, Microsoft Azure Functions, and Google Cloud Functions. These platforms provide tools and services for developing, deploying, and managing serverless applications, including integration with other cloud services such as databases, storage, and messaging systems.
Q11. What is your experience with DevOps methodologies like Agile or Lean?
Agile and Lean are popular methodologies used in DevOps environments to improve collaboration, communication, and efficiency across software development and operations teams. Agile is a methodology that emphasizes flexibility, collaboration, and iterative development, while Lean is a methodology that focuses on continuous improvement, waste reduction, and value delivery.
The agile methodology typically involves breaking down development projects into small, manageable pieces and working on each piece in short sprints or iterations. Teams collaborate closely and communicate regularly to ensure the development process is aligned with business goals and customer needs. The agile methodology emphasizes continuous feedback and adaptation, with regular review and adjustment of project goals and processes.
Lean methodology focuses on identifying and eliminating waste in the development process to deliver maximum customer value. The lean methodology emphasizes continuous improvement, with regular review and analysis of development processes to identify opportunities for improvement. The lean methodology also emphasizes the importance of collaboration and communication across teams, focusing on reducing silos and improving overall efficiency.
Agile and Lean methodologies can be used in DevOps environments to improve collaboration and efficiency across software development and operations teams. These methodologies can help ensure that development projects are aligned with business goals and customer needs and that development processes are continuously reviewed and improved for maximum efficiency and value delivery.
Q12. What is your experience with automated testing frameworks?
Automated testing frameworks are tools and platforms that enable developers to write and execute automated tests for software applications. These frameworks can help improve the speed and efficiency of software testing, as well as the quality and reliability of the tested applications.
There are many different types of automated testing frameworks, including unit testing frameworks, integration testing frameworks, and functional testing frameworks. These frameworks can be used to test various aspects of software applications, including code functionality, performance, and security.
Some popular automated testing frameworks include:
Selenium: a popular functional testing framework for web applications that supports various programming languages and platforms.
JUnit: a unit testing framework for Java applications that provides a set of assertions and annotations for testing code functionality.
pytest: a testing framework for Python applications that provides a flexible and extensible approach to test automation.
Cypress: a JavaScript-based end-to-end testing framework that supports browser automation and real-time testing.
Appium: a mobile testing framework that supports automated testing of iOS and Android applications.
Automated testing frameworks can help developers catch bugs and errors earlier in the development cycle, which can reduce development costs and improve the overall quality of the application. These frameworks can also help reduce the amount of manual testing required, which can save time and resources.
Q13. What is your experience with container orchestration tools like Kubernetes?
Container orchestration tools like Kubernetes are used to manage and automate containerized applications' deployment, scaling, and operation. These tools provide a way to manage the complex and dynamic infrastructure required for containerized applications, including load balancing, resource allocation, and container health monitoring.
Kubernetes is one of the most popular container orchestration tools available today. It provides a platform for deploying and managing containerized applications across a cluster of servers. Kubernetes allows developers to specify how many containers to run, how much CPU and memory to allocate to each container, and how to load balance traffic between containers. Kubernetes also provides features for managing container upgrades, rollbacks, and scaling, as well as tools for monitoring and logging container performance.
Other popular container orchestration tools include Docker Swarm, Apache Mesos, and Nomad. These tools provide similar functionality to Kubernetes, including features for deploying and managing containerized applications at scale.
Container orchestration tools can help simplify the management and scaling of containerized applications, reducing operational overhead and improving application reliability and availability. These tools can also help streamline the deployment process, allowing developers to focus on writing code and testing new features instead of managing infrastructure.
Q14. What is your experience with cloud-based database management services like RDS or Aurora?
Cloud-based database management services like Amazon RDS (Relational Database Service) and Aurora are designed to simplify the management of relational databases in the cloud. These services provide a way to set up, operate, and scale relational databases in the cloud without worrying about managing the underlying infrastructure.
Amazon RDS is a managed database service that makes it easy to set up, operate, and scale a relational database in the cloud. With RDS, you can choose from several popular database engines, including MySQL, PostgreSQL, Oracle, SQL Server, and MariaDB. RDS handles routine database tasks like backups, software patching, and replication, allowing you to focus on your applications and data.
Aurora is a MySQL and PostgreSQL-compatible relational database engine designed for the cloud. Aurora is fully managed and provides high performance, reliability, and scalability. Aurora uses a distributed architecture that allows it to scale out across multiple nodes, providing high availability and automatic failover.
Other popular cloud-based database management services include Google Cloud SQL, Microsoft Azure SQL Database, and Oracle Cloud Infrastructure Database.
Cloud-based database management services can help simplify the management of relational databases in the cloud, making it easier for developers to focus on building applications and managing their data. These services can also provide high availability, automatic backups, and disaster recovery, which can help ensure the reliability and availability of mission-critical databases.
Q15. What is your experience with load balancing and caching techniques?
Load balancing is a technique used to distribute incoming network traffic across multiple servers to improve performance, increase reliability, and provide redundancy in case of server failures. Load balancers can be hardware-based or software-based and can be deployed on-premises or in the cloud.
Caching is a technique used to improve application performance by storing frequently accessed data in a cache, which can be quickly retrieved without having to query the original data source. Caching can be implemented in various ways, including in-memory caching, distributed caching, and content delivery networks (CDNs).
Load balancing and caching are often used together to improve the performance and reliability of web applications. Load balancers can distribute traffic across multiple servers, which can improve application performance by reducing the load on individual servers. Caching can reduce the number of requests that need to be processed by the servers, which can further improve performance.
Many load balancing and caching technologies are available, including software-based solutions like NGINX, Apache HTTP Server, and HAProxy, and cloud-based solutions like Amazon Elastic Load Balancer, Google Cloud Load Balancing, and Azure Load Balancer. Popular caching solutions include Redis, Memcached, and Varnish.
Implementing load balancing and caching can be complex and requires careful planning and configuration to ensure optimal performance and reliability. When implemented correctly, load balancing and caching can significantly improve the performance and availability of web applications.
Q16. What is your experience with service discovery and registry tools like Consul or Zookeeper?
Service discovery and registry tools are used to manage the location and availability of services in a distributed system. These tools provide a way for services to discover and communicate with each other, even as the number and location of services change over time.
Consul is a service discovery and configuration management tool that provides features like service discovery, health checking, and key/value storage. Consul uses a distributed architecture, with multiple nodes in a cluster communicating with each other to provide a highly available and fault-tolerant service registry.
Zookeeper is a distributed coordination service that can be used for service discovery, configuration management, and synchronization. Zookeeper provides a hierarchical namespace for storing configuration information, as well as features like data watching and leader election.
Other popular service discovery and registry tools include etcd, Eureka, and Kubernetes service discovery. Service discovery and registry tools are critical components of modern distributed systems, enabling services to communicate with each other and dynamically adjust to changes in the system. These tools can help improve system availability and scalability and reduce the complexity of managing large, distributed applications.
Q17. What is your experience with message queuing systems like RabbitMQ or Kafka?
Message queuing systems are used to enable asynchronous communication between different parts of a distributed system. These systems allow messages to be sent between different components of a system without the components needing to be connected to each other directly.
RabbitMQ is a message queuing system that uses the Advanced Message Queuing Protocol (AMQP) to provide reliable message delivery between applications. RabbitMQ supports a variety of messaging patterns, including point-to-point messaging, publish/subscribe messaging, and request/reply messaging.
Kafka is a distributed streaming platform that provides a high-throughput, low-latency messaging system for large-scale data processing applications. Kafka uses a publish/subscribe messaging model, and provides features like partitioning, replication, and fault tolerance to ensure reliable message delivery.
Other popular message queuing systems include ActiveMQ, ZeroMQ, and Redis.
Message queuing systems are a critical component of many distributed systems, enabling asynchronous communication between different parts of the system and providing a way to handle large volumes of data. These systems can help improve system performance, reliability, and scalability, and are widely used in modern data processing and microservices architectures.
Q18. What is your experience with building automation tools like Jenkins or Travis CI?
Building automation tools are used to automate the process of building, testing, and deploying software applications. These tools are typically used in continuous integration and continuous delivery (CI/CD) pipelines, which aim to automate the entire software development lifecycle from code changes to production deployment.
Jenkins is an open-source automation server that can be used to build, test, and deploy software applications. Jenkins provides many plugins and integrations with other tools and services, making it a popular choice for building automation.
Travis CI is a hosted continuous integration service that provides an easy-to-use platform for building, testing, and deploying software applications. Travis CI supports various programming languages and provides integrations with popular version control systems like Git.
Other popular building automation tools include CircleCI, GitLab CI/CD, and TeamCity.
Building automation tools can help improve software quality and reduce time-to-market by automating repetitive tasks and ensuring consistent builds across development, testing, and production environments. These tools can also help quickly identify and fix bugs, improving overall system reliability and stability.
Q19. What is your experience with infrastructure monitoring tools like Datadog or New Relic?
Infrastructure monitoring tools are used to monitor the health and performance of infrastructure components like servers, network devices, and databases. These tools collect and analyze data on system performance and provide alerts and dashboards to help identify and troubleshoot issues.
Datadog is a cloud-based infrastructure monitoring platform that provides real-time visibility into the health and performance of infrastructure components like servers, databases, and cloud services. Datadog supports many integrations with popular tools and services, making it a popular choice for infrastructure monitoring.
New Relic is a cloud-based monitoring platform that provides real-time visibility into the performance and health of software applications and infrastructure. New Relic supports a wide range of programming languages and provides integrations with popular tools and services, making it a popular choice for application and infrastructure monitoring.
Other popular infrastructure monitoring tools include Prometheus, Nagios, and Zabbix.
Infrastructure monitoring tools can help improve system performance and reliability by providing real-time visibility into the health and performance of infrastructure components. These tools can help identify and troubleshoot issues more quickly and can help improve overall system uptime and availability.
Q20. What is your experience with security tools like HashiCorp Vault or AWS Secrets Manager?
Security tools like HashiCorp Vault and AWS Secrets Manager manage and protect sensitive data like passwords, API keys, and other credentials. These tools help ensure that sensitive data is stored securely and accessed only by authorized users and applications.
HashiCorp Vault is an open-source tool for managing and securing secrets, such as API keys, passwords, and certificates. Vault provides a centralized interface for managing secrets. It supports a wide range of authentication and access control mechanisms to ensure that secrets are accessed only by authorized users and applications.
AWS Secrets Manager is a fully-managed service that provides a secure and scalable way to store and manage secrets in the AWS Cloud. Secrets Manager allows you to store secrets like database credentials, API keys, and SSH keys and provides an API for accessing secrets securely from your applications. Other popular security tools for managing secrets include Azure Key Vault and Google Cloud KMS.
Security tools like HashiCorp Vault and AWS Secrets Manager can help improve security and compliance by providing a secure way to manage and access sensitive data like passwords and API keys. These tools can help reduce the risk of data breaches and other security incidents and can help ensure that sensitive data is accessed only by authorized users and applications.
Q21. What is your experience with networking concepts like firewalls, VPNs, and VPCs?
Networking concepts like firewalls, VPNs, and VPCs are essential to modern network infrastructure, especially in cloud computing.
Firewalls are a critical component of network security, used to filter traffic between different network segments and protect against unauthorized access. Firewalls can be implemented in hardware or software and configured to allow or block traffic based on rules and policies.
VPNs, or virtual private networks, provide a secure connection between two or more networks over the internet. VPNs are commonly used to provide remote access to corporate networks or to connect geographically distributed offices.
VPCs, or virtual private clouds, are isolated virtual networks within a public cloud provider like AWS or Azure. VPCs allow you to create and manage your virtual network, complete with subnets, routing tables, and security groups. This provides a high degree of control and security over your cloud infrastructure and allows you to create complex, multi-tiered applications in the cloud.
Other important networking concepts include load balancing, DNS, and network segmentation. Overall, a solid understanding of networking concepts is essential for anyone working in cloud computing or infrastructure management, as it is critical to ensuring that applications and services are secure, reliable, and performant.
Q22. What is your experience with disaster recovery and business continuity planning?
Disaster recovery and business continuity planning are critical components of IT infrastructure management. They involve developing and implementing strategies and procedures to ensure that systems and services can be recovered quickly and effectively during a disruption, whether a natural disaster, a cyber attack, or some other unforeseen event.
Disaster recovery typically involves implementing backup and restore procedures for critical systems and data and developing and testing plans for restoring services in the event of an outage or disruption. This may involve replicating data and systems to a secondary location, implementing redundant systems and infrastructure, or using cloud-based services for disaster recovery.
Business continuity planning is a broader process that involves identifying critical business functions and processes and developing plans to ensure that these can be maintained in the event of a disruption. This may include developing alternate work arrangements for employees, establishing redundant supply chains, and developing communication plans to keep stakeholders informed.
Overall, disaster recovery and business continuity planning are essential components of any IT infrastructure management strategy and require careful planning, implementation, and testing to ensure that systems and services can be quickly and effectively restored in the event of a disruption.
Q23. What is your experience with agile methodologies and sprint planning?
Agile methodologies are values and principles for software development that prioritize customer collaboration, iterative development, and rapid feedback. The Agile Manifesto outlines four key values:
Individuals and interactions over processes and tools
Working software over comprehensive documentation
Customer collaboration over contract negotiation
Responding to change by following a plan
One of the core practices of Agile methodologies is sprint planning, which is deciding what work will be done in the upcoming sprint. A sprint is a fixed period, typically one to four weeks, during which the development team works on a set of tasks that the product owner has prioritized.
During sprint planning, the development team works with the product owner to define the goals and objectives for the sprint and then breaks down those goals into smaller tasks that can be completed within the sprint timeframe. The team estimates the effort required for each task and commits to completing a set amount of work during the sprint.
Throughout the sprint, the team works together to complete the tasks and deliver working software at the end of the sprint. Daily stand-up meetings are held to discuss progress and identify any obstacles that need to be addressed. At the end of the sprint, the team holds a sprint review meeting to demo the completed work and gather stakeholder feedback.
They also hold a sprint retrospective to reflect on the process and identify areas for improvement. Agile methodologies and sprint planning can help teams to work more efficiently and deliver high-quality software that meets customer needs. Effective sprint planning requires strong communication, collaboration, and a commitment to continuous improvement.
Q24. What is your experience with debugging and troubleshooting complex systems?
Debugging and troubleshooting complex systems can be challenging, requiring a systematic and logical approach. Here are some tips that can help in this process:
Reproduce the problem: Try to replicate the issue to understand the exact conditions that lead to it. This can help in narrowing down the root cause of the problem.
Analyze the logs: Check the logs of the system to identify any errors or anomalies that can provide some hints about the problem.
Use monitoring tools: Employ monitoring tools to collect metrics on the system's behavior, performance, and resource usage. This can help identify patterns or trends contributing to the issue.
Use debugging tools: Use debugging tools like debuggers or profilers to trace the execution flow of the application and identify any bugs or performance bottlenecks.
Analyze the code: Analyze the code to identify any potential issues with the logic or implementation.
Collaborate: Involve the relevant teams and stakeholders in the debugging process, and share information about the issue to get their input and insights.
Experiment: Try different solutions or workarounds to see if they can resolve the issue.
A systematic and collaborative approach is key to effectively debugging and troubleshooting complex systems.
Q25. What is your experience with performance optimization techniques?
Performance optimization is improving the speed and efficiency of a system or application. Here are some techniques that can be used for performance optimization:
Profiling: Use profiling tools to identify performance bottlenecks and hotspots in the code. This can help identify the code areas that need to be optimized.
Code optimization: Optimize the code by reducing unnecessary computations, improving algorithm efficiency, and using appropriate data structures.
Caching: Use caching techniques to reduce the number of expensive operations, such as database queries or API calls, by storing frequently accessed data in memory.
Parallelization: Parallelize tasks to improve performance by using multiple threads or processes to perform concurrent operations.
Load balancing: Use load balancing techniques to distribute traffic across multiple servers, thereby improving performance and reducing downtime.
Database optimization: Optimize the database using appropriate indexing, partitioning, and query optimization techniques.
Hardware optimization: Optimize hardware using high-performance processors, memory, and storage devices.
Performance optimization requires a systematic and iterative approach involving analysis, experimentation, and measurement. It's also important to monitor the system's performance over time to ensure that it continues to meet the desired performance goals.
Q26. What is your experience with distributed systems and microservices architecture?
Distributed systems and microservices architecture are two related concepts in modern software development. Distributed systems are a collection of independent computers that work together to deliver a unified service or application. Microservices architecture is an approach to building applications that breaks down complex systems into small, independently deployable services that can be developed and managed separately.
Some common challenges of working with distributed systems and microservices architecture include:
Network latency and reliability.
Service discovery and orchestration.
Data consistency and integrity.
Security and authentication.
Monitoring and debugging.
To work with distributed systems and microservices architecture effectively, it is important to have a solid understanding of the underlying principles and challenges and experience with the tools and technologies commonly used in this space. This includes technologies such as containerization, orchestration platforms like Kubernetes, and distributed data stores like Apache Cassandra.
Q27. What is your experience with database backup and recovery procedures?
Database backup and recovery procedures are critical for ensuring the availability and recoverability of databases in the event of a disaster or other disruptive event. These procedures typically involve the following steps:
Identification of critical databases.
Backup frequency and retention.
Backup and recovery methods.
Testing.
Monitoring.
Disaster recovery planning.
Overall, database backup and recovery procedures are critical for ensuring the availability and recoverability of databases in the event of a disaster. It is important to prioritize critical databases, determine appropriate backup and recovery methods, regularly test procedures, monitor processes, and develop a comprehensive disaster recovery plan to ensure the organization can recover from a disaster with minimal disruption.
Q28. What is your experience with incident response and incident management?
Incident response and incident management are important components of IT service management. They involve preparing for and responding to unexpected events, such as system failures, cyber-attacks, or natural disasters, to minimize the impact of these events on service delivery.
Overall, incident response and incident management require careful planning, implementation, and monitoring to ensure that unexpected events are managed effectively and efficiently, with minimal impact on service delivery. It is important to establish clear incident response procedures and protocols, define roles and responsibilities, and implement incident response tools and technologies to enable a rapid and effective response to incidents.
Q29. What is your experience with change management and change control procedures?
Change management and change control procedures are important components of IT service management. They involve implementing a structured process for managing changes to IT systems and services to ensure that changes are made in a controlled and efficient manner, with minimal disruption to service delivery.
Change management typically involves the following steps:
Change request.
Change approval.
Change implementation.
Change review.
Change control procedures typically involve:
Establishing a formal process for managing changes, including documenting the change request.
Assessing the change.
Obtaining approval.
Implementing and reviewing the change.
This may involve establishing a change advisory board (CAB) to review and approve changes, as well as implementing change control tools and processes to manage the change request and implementation process.
Overall, change management and change control procedures are essential components of IT service management. They require careful planning, implementation, and monitoring to ensure that changes are made in a controlled and efficient manner with minimal disruption to service delivery.
To improve your chances of success in job interviews across various fields, be sure to follow us for more interview questions. Check out our previous articles by clicking on the links below.



Comments