Top Interview Questions on MLOps to Get your Job!!
- Yajendra Prajapati
- Apr 20, 2023
- 35 min read

As an MLOps professional, the primary responsibility is to ensure efficient and effective deployment of machine learning models in a production environment. It is a critical role that requires a strong understanding of software engineering, machine learning, and operations. For candidates who are new to this field, job interviews can be challenging, particularly given the interdisciplinary nature of MLOps. This article aims to provide a list of the top interview questions on MLOps that can help candidates prepare for their interviews and increase their chances of securing a job in this exciting field
Q1. What is the difference between MLOps and DevOps?
MLOps (Machine Learning Operations) and DevOps (Development Operations) are related but different concepts in software development.
DevOps is an approach to software development that emphasizes collaboration between development and operations teams, aiming to automate the software delivery pipeline and increase the speed and reliability of software releases. It involves using agile methodologies, continuous integration, continuous delivery (CI/CD), infrastructure as code (IAC), and other tools and practices to streamline software development and deployment.
MLOps is a specialization of DevOps that focuses specifically on machine learning (ML) applications. It involves applying DevOps principles and practices to developing and deploying ML models, including data preprocessing, model training, model testing, and model deployment. MLOps also includes monitoring and managing ML models in production, including updating models as new data becomes available.
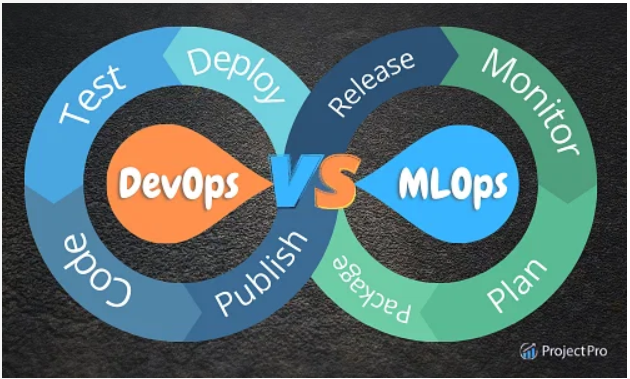
Source - ProjectPro
Q2. How do you create Infrastructure in MLOps?
Creating infrastructure in MLOps involves setting up the necessary computing resources, software environments, and data storage systems to support developing, training, and deploying machine learning models. Here are some key steps in creating infrastructure for MLOps:
Choose a cloud provider
Set up compute resources.
Create software environments.
Set up data storage.
Implement continuous integration and deployment (CI/CD).
Monitor and manage infrastructure.
By following these steps, MLOps teams can create a scalable, secure, and efficient infrastructure that supports the entire machine learning lifecycle, from data preprocessing to model deployment and management.
Q3. How can you create CI/CD pipelines for Machine Learning?
Creating continuous integration and continuous deployment (CI/CD) pipelines for machine learning (ML) involves automating the building, testing, and deploying of ML models as code changes are made. Here are some key steps in creating CI/CD pipelines for ML:
Version control: Before creating a pipeline, you must have your ML code and data under version control. You can use Git or other version control systems to manage changes to your code and data.
Build automation: Use a build automation tool like Jenkins or CircleCI to automatically build and test your code whenever a change is made to the repository. This ensures that your code is always working.
Model training: Use a container or virtual machine to train your ML model using a tool like TensorFlow or PyTorch. You can use your build automation tool to automate this process.
Model testing: Test your ML model using a separate testing dataset to ensure it is accurate and performs as expected. You can also use automated tests to validate the output of your model.
Model deployment: Once your model has passed testing, you can deploy it to a production environment. This can be done using containers or virtual machines or by deploying the model to a cloud-based service like AWS SageMaker or Azure ML.
Monitoring: Monitor your ML model in production to ensure it performs correctly and generates the expected output. You can use tools like Prometheus, Grafana, or CloudWatch to monitor your ML model's performance and output.
Model retraining: Over time, your ML model may become less accurate as new data becomes available. You can use your CI/CD pipeline to automatically trigger model retraining as new data becomes available.
Following these steps, you can create an automated CI/CD pipeline for your ML models, ensuring they are always up-to-date, accurate, and performing as expected.
Q4. What is model or concept drift?
Model or concept drift refers to the phenomenon where the statistical properties of the data used to train a machine learning model change over time, causing the model's performance to degrade. This can happen due to various reasons, such as changes in the underlying data distribution, changes in the relationship between the input features and the output, or changes in the data-generating process.
For instance, let's say you trained a machine learning model to predict fraudulent transactions in a financial dataset. However, over time, the characteristics of fraudulent transactions may change, making it difficult for the model to predict them accurately. As a result, the model may experience performance degradation, and its predictions may no longer be reliable.
To mitigate the effect of model or concept drift, it is essential to continuously monitor the model's performance and update it if required. This can involve retraining the model with new data, adjusting its parameters or hyperparameters, or adopting techniques such as online learning, ensemble learning, or transfer learning. By actively addressing model drift, organizations can ensure that their machine-learning models remain accurate and effective and that their business decisions remain well-informed.
Q5. How does monitoring differ from logging?
Monitoring and logging are two essential practices used in software engineering and DevOps to ensure the health and performance of systems. While they are related, they serve different purposes.
Logging involves recording events or transactions that occur within a system. This can include recording errors, warnings, and other system events that may be useful for troubleshooting and debugging. Logging is typically done by capturing log messages from various parts of the system and storing them in a centralized location for analysis.
On the other hand, monitoring is observing and measuring system performance and behavior in real time. It involves collecting metrics and data about system performance and analyzing them to detect potential issues or anomalies. Monitoring is often used to detect system-level problems such as CPU utilization, memory usage, network traffic, and system errors.
In summary, logging records events and transactions for later analysis and troubleshooting. At the same time, monitoring involves real-time observation and analysis of system performance and behavior to detect potential issues or anomalies. While both practices are important, they serve different purposes and are used to achieve different goals.
Q6. What testing should be done before deploying an ML model into production?
Before deploying an ML model into production, several testing types and techniques should be performed to ensure that the model performs as expected and meets the requirements of the end users. Here are some of the essential testing types for an ML model:
Unit Testing: Unit tests focus on testing individual components of the ML model, such as data preprocessing, feature extraction, and model training. Unit testing ensures that each model component works correctly and produces the expected output.
Integration Testing: Integration testing verifies that the different components of the ML model work together as intended. It involves testing the interactions between the data preprocessing, feature extraction, and model training components.
Validation Testing: Validation testing is performed to validate the model's output against a separate dataset, which was not used during the model training process. It ensures the model is not overfitting and generalizes well to unseen data.
Performance Testing: Performance testing determines the ML model's speed, accuracy, and resource utilization under different workloads and environments.
Security Testing: Security testing checks the ML model's security vulnerabilities to prevent data breaches, cyber-attacks, or data manipulation.
A/B Testing: A/B testing is used to compare the new model's performance against an existing model or baseline. It involves randomly assigning users to different models and comparing their performance to determine which model performs better.
By performing these testing types and techniques, we can ensure that the ML model is working correctly, provides accurate predictions, and meets the requirements of the end users. It also helps identify and mitigate potential issues before deploying the model into production.
Q7. What is the A/B split approach of model evaluation?
The A/B split approach is a common technique for evaluating the performance of machine learning models, especially in the context of testing and experimentation. It involves splitting a dataset or a user population into two groups - A and B - and comparing the performance of two different models or treatments, typically called Model A and Model B.
In machine learning, the A/B split approach is often used to compare the performance of two different models or versions of the same model. One group of users is randomly assigned to Model A, while the other group is assigned to Model B. The performance of each model is then evaluated by measuring relevant metrics such as accuracy, precision, recall, or AUC.
The A/B split approach is particularly useful when testing changes in a model, such as new features, algorithm modifications, or hyperparameter tuning. We can determine whether the changes are beneficial by comparing the performance of two models under identical conditions.
However, it's important to note that the A/B split approach requires careful consideration of factors such as sample size, statistical power, and randomization to ensure that the results are reliable and unbiased. It is also crucial to use appropriate statistical tests to compare the performance of the two models.
Q8. What is the importance of using version control for MLOps?
Version control is a crucial aspect of MLOps, as it allows developers and data scientists to manage and track changes to their machine learning models, code, and data. Here are some of the reasons why version control is important in MLOps:
Collaboration.
Reproducibility.
Experimentation.
Traceability.
Reusability.
In summary, version control is essential for managing and tracking changes to code, data, and models in MLOps. It enables collaboration, reproducibility, experimentation, traceability, and reusability, making it easier to develop, test, and deploy machine learning models.
Q9. What is the difference between A/B testing model deployment and Multi-Arm Bandit?
Both A/B testing and Multi-Arm Bandit (MAB) are popular techniques for model deployment in machine learning, but they differ in their approach to model selection and optimization.
A/B testing compares the performance of two different models or treatments, referred to as Model A and Model B. It involves randomly assigning users to different models and comparing their performance to determine which model performs better. A/B testing is a straightforward and reliable method for evaluating the effectiveness of different models, but it can be time-consuming and inefficient, especially when multiple models need to be compared.
On the other hand, Multi-Arm Bandit is a more dynamic and adaptive approach to model selection designed to optimize the selection of the best model over time. In MAB, the system continuously evaluates the performance of multiple models. It allocates resources based on their performance, giving more resources to models that perform well and fewer resources to models that perform poorly. MAB is more efficient than A/B testing because it adapts to model performance changes and allocates resources dynamically. Still, implementing it can be more complex and requires careful balancing of exploration (trying new models) and exploitation (using the best-known model).
In summary, A/B testing is a simple and effective method for comparing the performance of two models. At the same time, Multi-Arm Bandit is a more adaptive approach to model selection that continuously optimizes the allocation of resources to multiple models. The choice between the two approaches depends on the system's specific needs, including the number of models being tested, the rate of change in the system, and the resources available for testing.
Q10. What is the difference between Canary and Blue-Green strategies of deployment?
Canary and Blue-Green deployment strategies are popular techniques for deploying updates to software systems, including machine learning models. Still, they differ in their approach to managing risk during deployment.
In Blue-Green deployment, two identical environments, the Blue environment (existing system) and the Green environment (new system), are set up with only one serving traffic at a time. When a new version of the model or system is ready, it is deployed to the Green environment, and the traffic is redirected from the Blue environment to the Green environment. This allows the new version of the system to be tested and verified without affecting the existing users. Once the new version is fully verified, the traffic is switched back to the Blue environment.
On the other hand, Canary deployment involves deploying the new version of the model or system to a small subset of users (e.g., 1% or 5%) while the remaining users continue to use the existing system. The new version is then monitored for errors, performance issues, or other problems before gradually increasing the percentage of users directed to the new version. This allows the developers to detect and fix any issues before they affect a significant portion of users.
The key difference between these two deployment strategies is the level of risk involved. Blue-Green deployment involves deploying an entirely new environment and swapping traffic, which may cause significant downtime if issues arise. In contrast, Canary deployment is a more gradual approach that allows issues to be detected and resolved before affecting most users.
In summary, Blue-Green deployment involves switching traffic between two identical environments. Meanwhile, Canary deployment involves gradually increasing traffic to a new version of the system or model while monitoring for issues. The choice between these two strategies depends on the system's specific needs, including the level of risk tolerance, the rate of change in the system, and the resources available for testing.
Q11. Why would you monitor feature attribution rather than feature distribution?
Monitoring feature attribution is important in machine learning because it allows you to understand which features are driving the predictions made by the model. Feature attribution techniques such as Shapley values or partial dependence plots can help identify which features impact the model's output most, allowing developers to better understand the model's behavior and diagnose any issues that may arise.
In contrast, monitoring feature distribution is focused on ensuring that the distribution of input features remains consistent over time. While it is important to ensure that the distribution of input features is stable, monitoring feature distribution alone may not provide insight into how the model is making decisions or whether the model is behaving as expected.
For example, consider a model that predicts whether a loan application should be approved. If the distribution of applicant income shifts over time, adjusting the model to account for these changes may be important. However, monitoring feature attribution can help identify whether the model makes decisions based on other factors, such as gender or race, which could lead to biased or unfair outcomes.
In summary, monitoring feature attribution is important in machine learning because it allows developers to better understand the model's behavior and diagnose any issues that may arise. In contrast, monitoring feature distribution is important to ensure that the model is robust to changes in input data.
Q12. What are the ways of packaging ML Models?
There are several ways to package machine learning (ML) models, depending on the specific requirements of the deployment environment. Some common approaches are:
Model files: This involves packaging the trained model as a file that can be loaded into a runtime environment such as a web server or mobile app. The file format can vary depending on the framework used to train the model, such as TensorFlow, PyTorch, or Scikit-Learn.
Docker containers: Docker is a popular tool for packaging applications into containers that can be easily deployed to any environment. ML models can be packaged into Docker containers along with any dependencies needed for the model to run.
Serverless functions: Serverless platforms such as AWS Lambda or Google Cloud Functions allow ML models to be deployed as functions executed on demand. This approach can be useful for handling sporadic traffic or running quick, low-latency predictions.
REST APIs: RESTful APIs allow ML models to be exposed as web services that other applications can access. This approach can be useful for integrating ML models into larger applications or for exposing models to external users.
Mobile SDKs: Machine learning models can be packaged as software development kits (SDKs) that can be integrated into mobile applications. This approach can be useful for providing offline prediction capabilities on mobile devices.
In summary, there are several ways to package machine learning models, depending on the specific requirements of the deployment environment. The choice of packaging approach depends on factors such as the deployment environment, the scale of deployment, the required latency, and the available resources for managing the deployment.
Q13. What is the concept of “immutable infrastructure”?
Immutable infrastructure is an approach to software development and deployment in which infrastructure is designed to be static and unchangeable after deployment. This means that once an instance of infrastructure is created, it remains unchanged throughout its lifecycle. The primary benefit of immutable infrastructure is that it makes deployments faster and more reliable since there is less opportunity for human error and because immutable infrastructure is easy to roll back in case of issues.
This approach contrasts traditional infrastructure management models, where infrastructure is updated and patched manually. Immutable infrastructure is often implemented using virtual machines (VMs), containers, and serverless computing models. With containers and VMs, an image of the infrastructure is created and deployed across multiple environments, such as development, testing, and production. With serverless computing, code is executed in stateless compute containers, where each container is created anew for each execution.
Overall, immutable infrastructure is becoming increasingly popular in DevOps and cloud computing as it provides many benefits, including increased security, reliability, and consistency. By creating immutable infrastructure, organizations can reduce the risk of configuration drift, improve security, and simplify their applications and infrastructure deployment and maintenance.
Q14. Mention some common issues involved in ML model deployment.
ML model deployment can involve several challenges and issues. Here are some common ones:
Data bias: A model may be biased due to the training data used to develop it, leading to incorrect predictions in the production environment.
Model versioning: Keeping track of different versions of a model can be a challenge, especially if many different models are in use.
Scalability: Ensuring a model can handle the volume of requests it receives in production can be challenging, especially if the model was not designed to scale.
Performance: A model that performs well in a development or testing environment may not perform well in production due to differences in the data or infrastructure.
Monitoring: It is important to monitor a deployed model to ensure it continues performing as expected and to identify and address any issues.
Security: Ensuring that a model is secure and not vulnerable to attacks, such as adversarial attacks, is crucial.
Explainability: In some industries, such as healthcare or finance, it may be important to explain how a model arrived at its predictions, which can be a challenge for some types of models.
Addressing these issues is essential to ensuring the success of ML model deployment in production environments.
Q15. What is the difference between MLOps, ModelOps & AIOps?
MLOps, ModelOps, and AIOps are three different terms used in managing and deploying machine learning (ML) models. While they share some similarities, there are important differences between them. Here are brief descriptions of each:
MLOps: MLOps is applying DevOps principles and practices to develop, deploy, and manage ML models. This includes version control, continuous integration and delivery, monitoring, and automation of the ML workflow.
ModelOps: ModelOps is similar to MLOps but more focused on operationalizing ML models in production environments. ModelOps includes model performance monitoring, model retraining, and model governance, in addition to traditional DevOps practices.
AIOps: AIOps refers to using artificial intelligence (AI) and machine learning techniques to automate IT operations tasks such as monitoring, event correlation, and root cause analysis. AIOps uses ML models to analyze large volumes of data from IT infrastructure and applications to detect and diagnose issues and identify optimization opportunities.
In summary, MLOps and ModelOps focus on developing, deploying, and managing ML models. At the same time, AIOps is focused on automating IT operations using ML and AI techniques.
Q16. Define MLOps and how it is different from Data Science.
MLOps is a set of practices and principles for developing, deploying, and managing machine learning (ML) models in a production environment. MLOps combines the principles of software engineering and DevOps with the unique challenges of ML development to create a streamlined and automated workflow for building and deploying ML models.
MLOps involves several key activities, including:
Version control of ML code and data
Automated testing and validation of ML models
Continuous integration and delivery of ML models
Monitoring of ML models in production
Automated retraining and deployment of updated models
Collaboration and communication between data scientists, ML engineers, and operations teams
While data science involves the development of ML models, MLOps is focused on operationalizing and managing those models in a production environment. MLOps is different from data science in that it is more concerned with the practical considerations of deploying and managing ML models at scale rather than developing and validating individual models.
In summary, MLOps is a set of practices and principles for operationalizing and managing ML models in a production environment. At the same time, data science is focused on developing ML models using statistical and machine learning techniques.
Q17. What is the difference between MLOps and DevOps?
MLOps and DevOps share many similarities and are based on the same principles of continuous integration and delivery, automation, and collaboration. However, there are some key differences between the two.
MLOps focuses on the challenges of developing, deploying and managing machine learning (ML) models in a production environment. MLOps involves the application of DevOps principles and practices to the unique challenges of ML development, such as version control of data and models, automated testing and validation of models, and monitoring of models in production.
DevOps, on the other hand, is a broader set of practices and principles for software development and operations that includes continuous integration and delivery, infrastructure as code, automated testing, and collaboration between development and operations teams. DevOps is focused on the entire software development lifecycle, from planning to development to deployment and maintenance.
Another key difference between MLOps and DevOps is the nature of the artifacts that are being developed and deployed. In DevOps, the artifacts are typically software applications or services. In MLOps, the artifacts are ML models, which require specialized tooling and infrastructure to deploy and manage.
Q18. What are the risks associated with Data Science & how can MLOps overcome the same?
There are several risks associated with data science, such as:
Data quality issues: Poor data quality can lead to inaccurate or biased models.
Model bias: Models can incorporate biases from the data they are trained on, leading to discriminatory outcomes.
Overfitting: Models can be overfitting to training data, resulting in poor performance on new data.
Lack of interpretability: Some models, such as deep neural networks, can be difficult to interpret, making it challenging to understand why they are making certain predictions.
Security risks: Models can be vulnerable to attacks, such as adversarial attacks or model poisoning attacks.
MLOps can help mitigate these risks by providing a framework for developing, deploying, and managing ML models in a production environment. Some ways that MLOps can address these risks include:
Data quality monitoring and validation: MLOps can include automated data quality monitoring and validation to ensure that data is clean and appropriate for ML models.
Bias monitoring and mitigation: MLOps can include tools for monitoring and mitigating model bias, such as retraining models on more diverse data.
Model performance monitoring and validation: MLOps can include automated model performance monitoring and validation to ensure that models are not overfitting or performing poorly on new data.
Model interpretability: MLOps can include tools for interpreting and explaining models, such as generating explanations for model predictions.
Security monitoring and validation: MLOps can include security monitoring and validation to ensure that models are not vulnerable to attacks.
In summary, MLOps can help mitigate the risks associated with data science by providing a framework for developing, deploying, and managing ML models in a production environment.
Q19. Is model deployment the end of the ML lifecycle?
No, model deployment is not the end of the ML lifecycle. It is just one of the many stages in the ML lifecycle. The ML lifecycle typically consists of several stages, including:
Data collection and preparation.
Model training.
Model evaluation.
Model tuning.
Model deployment.
Model monitoring and maintenance.
As such, model deployment is an important stage in the ML lifecycle, but it is not the end of the process. Monitoring and maintenance are necessary to ensure the deployed model performs well and remains relevant in changing data or business requirements.
Q20. What is MLOps?
MLOps, short for Machine Learning Operations, applies DevOps principles and practices to developing, deploying, and managing machine learning (ML) models. MLOps aims to improve the efficiency, reliability, and scalability of the ML development process and ensure that ML models are deployed and managed in a production environment effectively.
MLOps involves a range of activities, including:
Data preparation and management.
Model development and training.
Model deployment and management.
Infrastructure management.
Collaboration and communication.
MLOps aims to increase the speed and efficiency of the ML development process, reduce the risk of errors or failures, and ensure that ML models are deployed and managed to meet business requirements and deliver value.
Q21. What are the benefits of MLOps?
MLOps, or Machine Learning Operations, brings several benefits to developing, deploying, and managing machine learning (ML) models. Some of the key benefits of MLOps include the following:
Improved efficiency.
Increased reliability.
Enhanced scalability.
Better collaboration.
Improved governance and compliance.
Faster time to market.
Better performance.
Overall, MLOps brings several benefits that can help organizations leverage ML models' power more effectively and derive greater value from their data.
Q22. How do you create infrastructure for MLOps?
Creating infrastructure for MLOps involves setting up a robust and scalable environment that can support the entire machine learning (ML) workflow, from data preparation and model training to deployment and monitoring. Here are the key steps involved in creating infrastructure for MLOps:
Choose a cloud provider.
Set up data storage.
Prepare the data.
Train the models.
Deploy the models.
Monitor and optimize.
Overall, creating infrastructure for MLOps requires careful planning and configuration to ensure that all the necessary services and resources are in place to support the entire ML workflow.
Q23. How to create CI/CD pipelines for machine learning?
Creating Continuous Integration/Continuous Deployment (CI/CD) pipelines for machine learning (ML) involves automating the building, testing, and deploying of ML models. Here are the key steps involved in creating CI/CD pipelines for ML:
Version Control.
Automated Testing.
Containerization.
CI/CD Tooling.
Infrastructure as Code.
Deployment.
Monitoring.
Overall, creating CI/CD pipelines for ML involves using tools and techniques to automate the model's development, testing, and deployment. This helps to ensure that the model is deployed quickly, reliably, and with high confidence in its performance.
Q24. Explain model/concept drift.
Model or concept drift refers to the phenomenon where the statistical properties of the data used to train a machine learning (ML) model change over time, leading to a drop in the model's accuracy and performance. This can occur due to changes in the underlying data distribution, which may be caused by changes in user behavior, shifts in market trends, or changes in the data collection process.
As a result of concept drift, the ML model may become less effective in making accurate predictions, and it may become necessary to update or retrain the model to adapt to the new data distribution. In some cases, it may be necessary to rebuild the entire ML pipeline to account for the changes in the data.
To detect and mitigate concept drift, it is important to continuously monitor the model's performance over time and compare it to the original performance metrics. If the performance drops below a certain threshold, triggering retraining of the model or updating the model's parameters may be necessary. Other strategies to mitigate concept drift include using ensemble models, which combine multiple models to improve performance, or active learning techniques, which adapt the model to the new data distribution by actively selecting new data points for training.
Detecting and addressing concept drift is an important part of the ML lifecycle and critical for ensuring the ongoing accuracy and effectiveness of ML models in production environments.
Q25. What is the difference between DevOps and MLOps?
DevOps and MLOps are two related but distinct disciplines. DevOps focuses on the automation and collaboration of processes between developers and operations teams, while MLOps focuses on developing, deploying, and managing machine learning models.
Here are some key differences between DevOps and MLOps:
Focus: DevOps is focused on automating and streamlining the development, testing, deployment, and maintenance of software applications, while MLOps is focused on doing the same for machine learning models.
Skillset: DevOps requires expertise in software development, testing, deployment, and infrastructure management, while MLOps requires expertise in data science, machine learning, and statistics, as well as experience with infrastructure management and deployment.
Tools: DevOps relies on tools such as version control systems, continuous integration, and delivery (CI/CD) pipelines, and containerization technologies, while MLOps requires specialized tools for data preparation, model training, and deployment, as well as tools for monitoring and measuring the performance of machine learning models.
Complexity: Machine learning models are more complex than traditional software applications and require specialized expertise and tools to develop, test, deploy, and maintain.
While there is some overlap between DevOps and MLOps, MLOps is a specialized discipline focusing on the unique challenges and requirements of developing and managing machine learning models.
Q26. What is TFDV, and how does it help with some of the pertinent challenges of MLOps?
TFDV stands for TensorFlow Data Validation, an open-source library Google developed for performing data validation on machine learning models. TFDV helps with some of the pertinent challenges of MLOps by providing a range of functionalities to help ensure the quality and consistency of the data used to train and evaluate machine learning models.
Here are some ways TFDV can help with some of the challenges of MLOps:
Data validation: TFDV can help validate the data used to train and evaluate machine learning models. It can detect missing values, anomalies, and other issues that could affect the quality and accuracy of the model.
Data drift detection: TFDV can detect changes in the statistical properties of the data over time, which can help identify data drift and prevent concept drift.
Schema management: TFDV can help manage the data schema used in machine learning models, ensuring that the data is consistent and compatible with the model.
Data profiling: TFDV can generate statistical summaries and visualizations of the data, providing insights into the distribution and quality of the data.
Integration with other tools: TFDV can be integrated with other MLOps tools, such as TensorFlow Extended (TFX), for end-to-end machine learning pipeline management.
Overall, TFDV can help with the data management and validation aspects of MLOps, which are critical for ensuring the accuracy and reliability of machine learning models in production environments.
Q27. Define train/serve skew and some potential ways to avoid them.
Train/serve skew, also known as model/data skew, refers to the difference between the performance of a machine learning model during training and its performance when deployed in production. This can be caused by various factors, such as differences in the data used during training and production, changes in the data distribution over time, and differences in the infrastructure or configuration between the training and production environments.
Here are some potential ways to avoid train/serve skew:
Data quality and consistency: Ensure that the data used during training and production is of high quality and consistent. This can be achieved through data validation, cleaning, and normalization.
Data sampling: Use representative data samples during training to ensure that the model can generalize well to new data.
Feature engineering: Ensure that the features used during training are relevant and informative for the target task and that they are available and consistent during production.
Model architecture and hyperparameters: Choose appropriate generalizable model architectures and hyperparameters that can perform well on a wide range of data.
A/B testing: Test the model in a controlled environment using A/B testing, which involves comparing the new model's performance against the existing one. This can help detect and quantify performance differences and identify areas for improvement.
Continuous monitoring: Monitor the model performance in production, detect and diagnose any performance issues, and adapt the model or data as needed.
Train/serve skew is a common challenge in machine learning deployment, but it can be mitigated through careful data management, feature engineering, model selection, and continuous monitoring and adaptation.
Q28. In addition to CI and CD, are there any other considerations unique to MLOps?
Several other considerations are unique to MLOps (Machine Learning Operations) beyond CI/CD (Continuous Integration/Continuous Deployment). Some of these considerations are:
Data management: Data is a critical part of machine learning workflows, and managing data pipelines, data versioning, data storage, and data quality is essential for successful MLOps.
Model versioning: In MLOps, models are also versioned, and it's important to keep track of different versions of models, including their code, configuration, hyperparameters, and weights.
Model monitoring: Once models are deployed, it's essential to monitor their performance, including accuracy, precision, recall, and other metrics. This helps detect and correct any issues that arise over time.
Model retraining: Models must be periodically retrained to maintain their performance and avoid model drift. Changes in data can trigger retraining models, changes in the environment, or other triggers.
Model deployment: Deploying models in production requires careful consideration of latency, scalability, and security factors. MLOps teams must ensure that models can be deployed quickly, reliably, and securely.
Explainability and transparency: MLOps teams need to ensure that models are transparent and explainable, especially when they make decisions that affect people's lives. Explainability and transparency can help build trust in the models and the organizations that deploy them.
Overall, MLOps involves many considerations beyond CI/CD, and successful MLOps requires a holistic approach that considers all aspects of the machine learning lifecycle.
Q29. What can be some of the deployment strategies borrowed from DevOps that can be utilized in MLOPs, and how to achieve them?
Several deployment strategies borrowed from DevOps can be utilized in MLOps. Here are some of them:
Blue-Green Deployment: This deployment strategy involves creating two identical environments - the blue environment (the currently active environment) and the green environment (the environment being prepared for deployment). Once the green environment is ready, traffic is switched from the blue environment to the green environment. In MLOps, this strategy can deploy new models in the green environment while keeping the current model running in the blue environment until the new model is tested and validated.
Canary Release: This deployment strategy involves deploying new features or changes to a small group of users before deploying them to the entire user base. In MLOps, this strategy can be used to first deploy new models to a small subset of users to validate their performance before deploying them to the entire user base.
Rolling Deployment: This deployment strategy involves deploying changes to a small set of servers simultaneously, gradually rolling out the changes across the entire infrastructure. In MLOps, this strategy can be used to deploy new models to a small subset of servers to ensure they function correctly before deploying them to the entire infrastructure.
Infrastructure as Code: Infrastructure as Code (IaC) is a practice where infrastructure is defined and managed using code. In MLOps, IaC can be used to define and manage infrastructure for machine learning, such as data pipelines, model training environments, and model deployment environments.
To achieve these deployment strategies in MLOps, organizations can use automation tools such as Kubernetes, Docker, and Terraform. These tools can help automate the deployment, testing, and validation of machine learning models and infrastructure, providing greater agility and scalability in MLOps. Additionally, organizations can implement monitoring and alerting tools to track the performance of models in production and use feedback loops to continuously improve their models and infrastructure.
Q30. What is the difference between a CPU and a GPU, and how are they used in machine learning?
CPUs (Central Processing Units) and GPUs (Graphics Processing Units) are both types of computing used in computing, but their design and capabilities differ. CPUs are general-purpose processors designed to handle a wide range of computing tasks, while GPUs are specialized processors optimized for the parallel processing of large amounts of data.
In machine learning, GPUs are commonly used for training and inference tasks because of their ability to perform large amounts of parallel computations in a relatively short time. This is due to their architecture, which includes many more processing cores than a CPU and is optimized for handling large amounts of data simultaneously.
Here are some of the key differences between CPUs and GPUs:
Cores: CPUs typically have a few processing cores, while GPUs can have hundreds or thousands of processing cores.
Clock speed: CPUs have a high clock speed, which enables them to handle single-threaded tasks quickly. In contrast, GPUs have a lower clock speed, but they can handle many tasks in parallel.
Memory: CPUs have a small amount of memory cache that is optimized for low latency and fast access times. GPUs have a larger memory bandwidth, which enables them to move data in and out of memory much faster than CPUs.
Q31. What is Docker, and how is it used in MLOps?
Docker is an open-source platform that provides a way to package, distribute, and run applications in containers. Containers are lightweight, portable, and self-contained environments that run applications consistently across different environments, such as development, testing, and production. In the context of MLOps, Docker containerizes machine learning applications, such as models and data pipelines, to make them more portable and easier to manage.
Some of the ways Docker is used in MLOps include:
Packaging machine learning applications: Docker can package machine learning applications, such as models, data pipelines, and web services, into containers. These containers can be easily shared and distributed, making it easier for teams to collaborate and deploy applications consistently across different environments.
Isolating dependencies: Docker containers provide an isolated environment for running machine learning applications, which can help ensure that the applications run consistently across different environments, even if the underlying dependencies, such as operating system libraries and runtime environments, differ.
Reproducing experiments: Docker can create reproducible environments for machine learning experiments. By packaging the entire environment, including the dependencies and libraries used to train the model, in a container, the same environment can be easily recreated, making it easier to reproduce experiments and results.
Streamlining deployment: Docker can streamline the deployment of machine learning applications by allowing teams to package and distribute applications in containers easily deployed to production environments using container orchestration tools, such as Kubernetes.
Docker is a powerful tool for containerizing machine learning applications, making them more portable, consistent, and easier to manage across different environments. Docker is increasingly used in MLOps to streamline the entire machine learning workflow, from development to production.
Source - Docker
Q32. What is Kubernetes, and how is it used in MLOps?
Kubernetes is an open-source container orchestration platform used to automate containerized applications' deployment, scaling, and management. In the context of MLOps, Kubernetes deploys and manages machine learning models in production environments.
Kubernetes provides a range of features that are particularly useful for deploying and managing machine learning models, including:
Scaling: Kubernetes can automatically scale the number of replicas of a model based on demand. This can help ensure that the model is always available to handle requests, even during periods of high traffic.
Self-healing: Kubernetes can detect and automatically recover from failures, such as crashed model replicas. This can help ensure that the model is always available and performing as expected.
Resource management: Kubernetes can allocate resources, such as CPU and memory, to individual model replicas based on demand. This can help ensure that the model is optimized for performance and efficiency.
Rollbacks: Kubernetes can roll back to previous versions of a model if issues are detected. This can help ensure that the model is always performing as expected and can help reduce downtime and errors.
In addition to these features, Kubernetes provides a range of tools and APIs that can be used to automate the deployment and management of machine learning models. For example, Kubernetes can be integrated with popular machine learning frameworks, such as TensorFlow and PyTorch, to automate the deployment of models.
Some of the ways Kubernetes is used in MLOps include:
Deploying machine learning models as containers.
Managing machine learning infrastructure.
Automating machine learning workflows.
Overall, Kubernetes is a powerful tool for deploying and managing machine learning models in production environments and is increasingly being used in MLOps to automate the entire machine learning workflow.

Source - iguazio
Q33. What is version control, and how is it used in MLOps?
Version control is a software development practice that tracks changes to source code or other artifacts over time. In the context of MLOps, version control refers to tracking changes to machine learning artifacts, such as models, data, and code.
Version control systems (VCS) allow multiple users to work on the same code or artifact simultaneously while keeping track of changes made by each user. This enables developers to collaborate on projects more effectively while providing a history of changes that can be used to revert to previous versions or troubleshoot issues.
In MLOps, version control is used to track changes to machine learning artifacts, such as:
Code: Machine learning projects typically involve writing code for data preparation, feature engineering, model training, and evaluation. Version control allows developers to track changes to this code over time and collaborate on it more effectively.
Data: Machine learning models rely on data to make predictions. Version control allows data scientists to track changes to datasets, such as new data sources, preprocessing steps, or labeling improvements.
Models: Machine learning models are the primary output of machine learning projects. Version control allows data scientists to track model changes over time, such as hyperparameter tuning, feature selection, or model architectures.
Version control systems can also help ensure the reproducibility of machine learning experiments by making it easy to recreate the same environment used to train a model at a specific time.
Some of the most popular version control systems used in MLOps include Git, Subversion, and Mercurial. These tools provide features such as branching, merging, and conflict resolution, essential for collaborating on machine-learning projects with multiple team members.

Source - Analytics Vidhya
Q34. What is continuous integration and deployment (CI/CD), and how are they used in MLOps?
Continuous Integration and Deployment (CI/CD) is a software development approach that aims to automate the process of building, testing, and deploying software applications. In MLOps, CI/CD refers to automating machine learning model build, test, and deployment.
CI/CD involves the following steps:
Continuous Integration: Developers integrate their code changes into a shared repository, which triggers an automated build process. The build process compiles the code, runs automated tests, and produces a build artifact, such as a Docker image.
Continuous Delivery: The build artifact is automatically deployed to a staging environment for further testing and validation. This environment is similar to the production environment but may contain fewer data or have other differences.
Continuous Deployment: If the build artifact passes all tests and validation, it is automatically deployed to the production environment. This can be done gradually, using techniques such as canary releases or blue-green deployments to minimize the risk of downtime or errors.
In MLOps, CI/CD involves applying these principles to the machine learning workflow. This includes automating the process of building, testing, and deploying machine learning models and the associated infrastructure, such as containers or serverless functions.
Some of the ways CI/CD is used in MLOps include:
Automating building and testing machine learning models, including data preparation, feature engineering, model training, and evaluation.
Using version control systems to manage machine learning artifacts, including models, data, and code.
Automating the deployment of machine learning models to production environments using techniques such as containers, Kubernetes, or serverless functions.
Implementing monitoring and logging systems to track the performance of machine learning models in production and using this feedback to improve the model over time.
By applying CI/CD principles to the machine learning workflow, MLOps aims to improve machine learning projects' speed, quality, and reliability while reducing the risk of errors or downtime.
Q35. How do you evaluate the performance of a machine learning model in production?
Evaluating the performance of a machine learning model in production involves monitoring its performance over time and comparing it to the expected performance metrics. Here are some steps that can be taken to evaluate the performance of a machine-learning model in production:
Define metrics: The first step is to define the metrics that will be used to evaluate the model's performance. The metrics can be specific to the problem being solved, such as accuracy, precision, recall, and F1 score, or they can be business metrics, such as revenue or customer satisfaction.
Collect data: Collect data from the model in production, including inputs and outputs, performance metrics, and other relevant information. This can be done using monitoring tools or logging systems.
Analyze data: Analyze the data to identify patterns or trends in the model's performance over time. Look for changes in the performance metrics and investigate the causes of any anomalies.
Take action: Based on the analysis, take action to improve the model's performance. This can involve retraining the model on new data, adjusting the model's hyperparameters, or making changes to the input data or feature engineering.
Evaluate results: After taking action, evaluate the results to determine if the model's performance has improved. This may involve comparing the performance metrics before and after the changes or running experiments to test different configurations.
Iterate: Finally, iterate on monitoring, analyzing, and improving the model's performance over time. This involves continuously collecting data, analyzing it, and taking action to improve the model's performance.
In summary, evaluating the performance of a machine learning model in production involves:
Monitoring its performance over time.
Analyzing the data to identify patterns and anomalies.
Taking action to improve the model's performance.
Evaluating the results.
This process is iterative and ongoing and requires monitoring tools, data analysis, and domain expertise.
Q36. What is MLOps, and how does it differ from DevOps?
MLOps (Machine Learning Operations) is the application of DevOps practices to the machine learning workflow. MLOps aims to streamline the entire machine learning lifecycle, from data preparation and model training to deployment and monitoring.
DevOps is a software development approach that emphasizes collaboration and communication between developers and IT operations teams. DevOps practices include continuous integration, continuous delivery, and automated testing, which help to improve the quality and reliability of software applications while reducing the time required to deliver new features and updates.
MLOps builds on these DevOps practices and extends them to the machine learning workflow. In addition to the traditional DevOps practices, MLOps also includes specialized tools and processes for managing the unique challenges of machine learning, such as versioning of models and data, model drift, and reproducibility.
Some of the key differences between DevOps and MLOps include:
Data-centricity: Machine learning models rely on data, which makes data management and governance a critical part of MLOps. This means that MLOps focuses more on data engineering, quality, and lineage than traditional DevOps.
Model-centricity: In MLOps, models are treated as first-class artifacts like code. This means that model versioning, testing, and deployment are given the same level of attention as code.
Deployment: Deploying machine learning models requires specialized infrastructure, such as containers, Kubernetes, or serverless platforms. MLOps involves managing this infrastructure to ensure that models are deployed reliably and consistently.
Monitoring: Machine learning models are dynamic, and their performance can degrade over time due to data or concept drift. MLOps involves monitoring models in production to detect these issues and trigger retraining or model updates.
In summary, MLOps is an extension of DevOps that focuses on the unique challenges of managing the machine learning lifecycle, including data management, model versioning, specialized infrastructure, and monitoring. MLOps aims to increase machine learning projects' efficiency, reliability, and scalability by applying DevOps principles and tools to the machine learning workflow.
Q37. What is the difference between a machine learning model and a traditional software application?
Machine learning models and traditional software applications serve different purposes and characteristics.
A traditional software application is typically designed to perform specific tasks, following predetermined rules and logic. These applications use traditional programming languages and are often designed to process structured data. The output of a traditional software application is deterministic and predictable, meaning that the same input will always produce the same output.
In contrast, a machine learning model is designed to learn from data and improve its performance over time. Machine learning models are built using algorithms that can detect patterns and relationships in data and make predictions or decisions based on that data. Machine learning models can process structured and unstructured data, making them useful for various applications. The output of a machine learning model is probabilistic, meaning that it provides a degree of certainty about its predictions or decisions.
Another key difference between traditional software applications and machine learning models is how they are built and maintained. Traditional software applications are typically built using predefined rules and require significant manual effort to update or modify. Machine learning models, on the other hand, can adapt and improve over time as they are trained on more data. However, building and maintaining machine learning models require specialized skills, data, and computational resources.
The main differences between a machine learning model and a traditional software application are that machine learning models can learn from data and improve their performance over time, process both structured and unstructured data, and provide probabilistic outputs. Building and maintaining machine learning models also requires specialized skills, data, and computational resources.
Q38. What are the different stages of the machine learning lifecycle?
The machine learning lifecycle consists of several stages that must be followed to develop and deploy a machine learning model. These stages include:
Problem Definition: In this stage, the business problem the machine learning model intends to solve is defined. The problem definition stage involves understanding the business requirements, defining the objectives, and identifying the success metrics.
Data Collection: In this stage, data is collected from various sources that will be used to train the machine learning model. Data collection involves identifying the sources, selecting the relevant data, and cleaning the data to ensure that it is accurate and consistent.
Data Preparation: In this stage, the collected data is preprocessed and transformed into a format that can be used to train machine learning models. Data preparation involves data cleaning, feature engineering, feature selection, and data normalization.
Model Training: In this stage, the machine learning model is trained on the prepared data. Model training involves selecting an appropriate machine learning algorithm, tuning the algorithm's hyperparameters, and evaluating the model's performance.
Model Evaluation: In this stage, the trained machine learning model is evaluated to determine its accuracy and reliability. Model evaluation involves using a validation dataset to measure the model's performance.
Model Deployment: In this stage, the trained machine learning model is deployed into production. Model deployment involves integrating the model into the production environment and testing it to ensure it performs as expected.
Model Monitoring and Maintenance: In this stage, the deployed machine learning model is monitored to ensure it performs as expected. Model monitoring involves tracking the model's performance, detecting errors and anomalies, and updating the model to address any issues.
In summary, the machine learning lifecycle consists of several stages that must be followed to develop and deploy a machine learning model. These stages include problem definition, data collection, data preparation, model training, model evaluation, model deployment, and model monitoring and maintenance.
Q39. What is a feature, and how is it used in machine learning?
In machine learning, a feature is an individual measurable property or characteristic of a phenomenon that can be used to make predictions or classify data. Features are used to represent the input variables or predictors that are used to train machine learning models.
For example, in a classification problem where the goal is to predict whether an email is spam, features can include the length of the email, the presence of certain words or phrases, the sender's email address, and the subject line. These features can then be used to train a machine learning model to predict whether an email is spam.
Features are used in machine learning to represent the input variables or predictors used to train machine learning models. The quality and relevance of the features used to train a model can significantly impact its performance. The process of selecting, engineering, and transforming features is known as feature engineering, and it is a critical step in building accurate and reliable machine learning models.
Feature engineering involves selecting and transforming features to capture relevant information that can help improve model performance. For example, features can be transformed by normalizing, scaling, or one-hot encoding them to improve model convergence and accuracy. Feature engineering also involves selecting the most relevant features to include in a model to avoid overfitting and improve generalization.
In summary, features are an essential component of machine learning models. They represent the input variables or predictors used to train models and are critical to building accurate and reliable models. Feature engineering is critical in selecting, transforming, and engineering features to improve model performance.
Q40. What is a data pipeline, and how is it used in machine learning?
A data pipeline is a set of processes and tools used to collect, transform, and move data from one location to another. In machine learning, a data pipeline is used to prepare data for training machine learning models.
Data pipelines are used in machine learning to automate collecting, cleaning, transforming, and preparing data for training models. Data scientists use pipelines to move data from various sources into a centralized location, such as a data warehouse or data lake. The data is then processed and transformed using tools such as Apache Spark or TensorFlow to prepare it for machine learning algorithms.
Once the data has been prepared, it is used to train machine learning models. The output of the machine learning models is then used to make predictions or automate decisions.
Data pipelines are important in machine learning because they enable data scientists to streamline collecting, cleaning, and preparing data for training models. This reduces the time spent on manual data preparation tasks, allowing data scientists to focus on developing and improving machine learning models.
Moreover, data pipelines ensure that the data used to train machine learning models is accurate, complete, and consistent. This is important because machine learning models' accuracy and reliability depend on the quality of the data used to train them.
Q41. What is a data warehouse, and how is it used in machine learning?
A data warehouse is a large integrated data repository for analysis and reporting. It supports business intelligence activities by consolidating data from different sources into a centralized location.
Data warehouses are used in machine learning to provide a reliable and consistent data source for training machine learning models. By integrating data from various sources into a single location, data warehouses enable data scientists to access high-quality data that has been cleansed, transformed, and enriched to support machine learning workflows.
Data warehouses also enable data scientists to perform complex data analysis and generate insights that can be used to inform machine learning models. For example, by analyzing data stored in a data warehouse, data scientists can identify patterns, trends, and anomalies that can be used to inform feature engineering and model selection.
Additionally, data warehouses are designed to support complex queries and analytics, making it easier for data scientists to perform ad-hoc queries and data exploration to identify data quality issues and inconsistencies affecting machine learning model performance.
In summary, data warehouses are used in machine learning to provide a reliable, consistent, and high-quality source of data that supports the development and deployment of machine learning models.
Q42. What is the difference between batch processing and stream processing?
Batch processing and stream processing are two different approaches to processing data.
Batch processing is a method of processing large volumes of data collected over time, such as a day, a week, or a month. The data is stored and processed in batches, meaning that the data is collected, stored, and then processed later. Batch processing is typically used for tasks that don't require real-time processing, such as generating reports, performing analytics, and running scheduled data backups.
On the other hand, stream processing is a method of processing data in real time as it is generated. Data is continuously collected, processed, and analyzed in stream processing as it flows through a system. Stream processing is typically used for applications that require real-time data processing, such as fraud detection, monitoring social media, and analyzing sensor data.
The key difference between batch processing and stream processing is the data processing timing. Batch processing is designed for processing large volumes of data simultaneously, while stream processing is designed for processing data as it is generated in real time. Additionally, batch processing is often used for complex data transformations and analytics, while stream processing is focused on real-time monitoring and analysis.
Q43. What is a data lake, and how is it used in machine learning?
A data lake is a large centralized repository that allows the storage of vast amounts of structured, semi-structured, and unstructured data. Unlike traditional data warehouses, data lakes store raw data in its native format without imposing predefined schema or structure.
Data lakes are used in machine learning to provide a unified storage location for all the relevant data for training, validating, and deploying machine learning models. Machine learning algorithms require large amounts of data to learn patterns and make predictions, and data lakes provide a cost-effective solution for storing and managing large volumes of data.
By leveraging the scalability and flexibility of data lakes, data scientists and machine learning engineers can collect and store data from various sources, including databases, social media, and sensors. They can then use this data to train machine learning models and analyze data to derive valuable insights.
Data lakes allow easy integration with other data processing tools and machine learning frameworks, such as Apache Spark and TensorFlow. Additionally, data lakes can support data science workflows, including data preparation, feature engineering, and model evaluation, by providing access to high-quality data in a unified location.
To improve your chances of success in job interviews across various fields, be sure to follow us for more interview questions. Check out our previous articles by clicking on the links below.



Comments